
And so we arrive at the final station. This series on replicating types in Swift ends with this post. I will no doubt revisit various aspects of replicating types in other posts, but we are closing out the series proper here.
To recap, we have moved through Conflict Free Replicated Data Types (CRDTs) from the perspective of a Swift app developer, beginning with what they are and why they are useful, the mathematical features they must possess, the tricks and tools you can use to build them, and finishing with a series of posts on different types of CRDTs, from basic register types that are well suited to simple atomic properties, up to more complex array and dictionary types capable of recursive merging.
In this post, I’ll bring all of this together into a real world app. We won’t concentrate on details of SwiftUI or Combine, which are used throughout the app, but the code is there if these aspects intrigue you. Instead, the focus will be on model and data handling.
The app in question is a distributed data, note taking app. Unlike an app like eg Slack, which are built around a central server, this app allows edits to be made on any device, even if you are offline for days. Even better, when changes are synced up, edits get merged together in ways that seem logical to the user. When you make two different spelling corrections to the same note on two different devices, both corrections will survive the sync.
Introducing Decent Notes
Our decentralized app has to have a name; in line with the focus of this site, and the wholesome goodness of all Swift developers, the only name that fit was “Decent Notes”. It’s a simple enough app with some somewhat perplexing features that have been introduced purely for the educational purpose of accentuating the usage of the replicating types in our toolkit.
Of course, Decent Notes allows you to add and delete notes, and reorder them. In the note editing screen, you can set a title, and edit the note’s text, but you can also set a note priority, and choose from a few fixed tags, such as “Work” and “Home”.

Each of these features is backed by an appropriate replicating data type. A title, which can be treated as a single atomic string, will be handled differently to the body of note content, where we want edits to be merged when they happen concurrently. We’ll choose replicating types appropriate for our goals in each case.
Running Decent Notes Yourself
The source code is available on GitHub. The app uses CloudKit to transfer data between devices. To build your own copy, you need to change a few things:
- Change the app bundle id to one in your own App Store Connect account (eg
com.mycompany.decentnotes). - Go into the Capabilities tab of the app target, and make sure that iCloud is active, with CloudKit checked, and set the container identifier there (eg
iCloud.com.mycompany.decentnotes). - Finally, locate the source file
AppStorage.swiftand, in the functionmakeCloudStore, replace the existing iCloud container with the one you just set.

A Decent Note
The goal is to build up a model for Decent Notes out of replicating types, such that the model itself is effectively one big replicating type. To keep things simple, we will just store all data for all notes in one file, and sync it to CloudKit as a single file. In a shipping app, you would have to think more about how to partition the data into smaller chunks, to reduce the memory footprint, and the transfer load to and from the cloud.
The main model type is the Note.
struct Note: Identifiable, Replicable, Codable, Equatable {
enum Priority: Int, Codable {
case low, normal, high
}
enum Tag: String, Codable, CaseIterable {
case home, work, travel, leisure
}
var id: UUID = .init()
var title: ReplicatingRegister<String> = .init("")
var text: ReplicatingArray<Character> = .init()
var tags: ReplicatingSet<Tag> = .init()
var priority: ReplicatingRegister<Priority> = .init(.normal)
var creationDate: Date = .init()
Two of these properties are not like the others. Notice that id and creationDate don’t seem to be replicable at all. In actual fact, they are, because immutable types can replicate by default. When you create a new note, the two properties are set, and they never change again. They are simply copied. Merging constant properties is trivial, because the merging values should always be the same.
I’ve chosen to use a register for the title. This will mean changes are atomic — there will be no partial merging. One of the two merged values will always win, and changes made in the other will be discarded. For a simple string like a title, this is acceptable. If it is important to your app to allow partial merges, you could use a ReplicatingArray for the title, just as for the content text, with the knowledge that there is a cost to that in data size.
The main text of the note is built on the ReplicatingArray, with Character as the element type.
var text: ReplicatingArray<Character> = .init()
We want to allow simultaneous edits to be merged in a logical way for the user. This approach would even work for a multiple user, collaborative text editor like Google Docs.
The tags and priority properties have been included mostly for educational purposes.
var tags: ReplicatingSet<Tag> = .init()
var priority: ReplicatingRegister<Priority> = .init(.normal)
The tags demonstrate how you could use a replicating set type. You can add and remove tags on different devices, and have those partial changes merged together, rather than one set of changes overriding the other, as would be the case with a register type.
The priority is different. For that, we do want an atomic outcome. If you chose a priority of 1 on your iPhone, and 2 on your iPad, we don’t want the merged result to be 1.5. No, one of the two has to win. It has to be an atomic outcome, and a register is appropriate for that.
A Decent NoteBook
The other part of the model is the NoteBook. This is what contains the collection of notes.
struct NoteBook: Replicable, Codable, Equatable {
private var notesByIdentifier: ReplicatingDictionary<Note.ID, Note> {
didSet {
if notesByIdentifier != oldValue {
changeVersion()
}
}
}
private var orderedNoteIdentifiers: ReplicatingArray<Note.ID> {
didSet {
if orderedNoteIdentifiers != oldValue {
changeVersion()
}
}
}
private(set) var versionId: UUID = .init()
private mutating func changeVersion() { versionId = UUID() }
var notes: [Note] {
orderedNoteIdentifiers.compactMap { notesByIdentifier[$0] }
}
This code is complicated a little by the use of a versionId. This is just a UUID that is changed every time an edit is made. The purpose of it is simply to quickly identify if a change has been made since the last time we synced, so we can determine if an upload is needed. If we compare the current versionId to the one we know is in the cloud, we know if the data needs to be uploaded again or not.
There are two main properties used in NoteBook. The first is a replicating dictionary which holds the actual notes: notesByIdentifier. To track the order of notes, so we can support manual sorting and moving, we have the orderedNoteIdentifiers replicating array.
I can hear some of you protesting from here: “Why not just put the notes in a replicating array, and you are done?”. The problem is that the array type doesn’t understand identity. If we made changes to a note, and updated the array, it would effectively save it as a new note, deleting the original one. We would lose all the advantages of partial merging that CRDTs provide.
As we saw in an earlier post, the ReplicatingDictionary type has the nice property that when the values are themselves Replicable, corresponding entries will get properly merged. This is essential to having our decentralized notes syncing up how the user expects them to.
Decent Syncing
The CloudStore.swift file does the heavy lifting of uploading the data to CloudKit, and downloading what other devices have uploaded. The code uses Combine heavily, and we won’t go into it. You can read a little about it here, and perhaps I will cover it in more depth in other posts. For now, we just take for granted that it will do its job properly.
When data is downloaded by the CloudStore class, it informs the DataStore object, which unpacks it using a JSONDecoder, and then merges the remote data with the local.
func receiveDownload(from store: CloudStore, _ data: Data) {
if let notebook = try? JSONDecoder().decode(NoteBook.self, from: data) {
merge(cloudNotebook: notebook)
}
}
The merge method looks like this.
func merge(cloudNotebook: NoteBook) {
metadata.versionOfNotebookInCloud = cloudNotebook.versionId
noteBook = noteBook.merged(with: cloudNotebook)
save()
}
That is simple enough. It is saving the version id we discussed earlier, then merges and saves the local noteBook with that from the cloud.
The merging code of the NoteBook type is the devil in the details.
func merged(with other: NoteBook) -> NoteBook {
var new = self
new.notesByIdentifier = notesByIdentifier.merged(with: other.notesByIdentifier)
// Make sure there are no duplicates in the note identifiers.
// Also confirm that a note exists for each identifier.
// Begin by gathering the indices of the duplicates or invalid ids.
let orderedIds = orderedNoteIdentifiers.merged(with: other.orderedNoteIdentifiers)
var encounteredIds = Set<Note.ID>()
var indicesForRemoval: [Int] = []
for (i, id) in orderedIds.enumerated() {
if !encounteredIds.insert(id).inserted || new.notesByIdentifier[id] == nil {
indicesForRemoval.append(i)
}
}
// Remove the non-unique entries in reverse order, so indices are valid
var uniqueIds = orderedIds
for i in indicesForRemoval.reversed() {
uniqueIds.remove(at: i)
}
new.orderedNoteIdentifiers = uniqueIds
return new
}
This is more code than I would like. In theory, this could be reduced down to two simple calls to the merged function, like this…
var new = self
new.notesByIdentifier = notesByIdentifier.merged(with: other.notesByIdentifier)
new.orderedNoteIdentifiers = orderedNoteIdentifiers.merged(with: other.orderedNoteIdentifiers)
return new
So what’s the problem? Why can’t we have our 4 line merging function?
When ReplicatingArray is Indecent
The problem really comes down to using a ReplicatingArray to track the sort order. As already mentioned, the array type doesn’t have any concept of identity, so there are situations where seemingly straightforward edits can lead to duplicate entries.
To see how, imagine we begin with the array of identifiers fully synced up on two devices. On the first device we then move the first Note to the second position, and — at the same time — we do the same on the other device. The ReplicatingArray records these changes not as moves, but as deletions and insertions. Both devices will record the deletion at the first location, and then will insert a new entry. The problem is, because they each create their own insertion, after things are synced, the identifier of the moved note will be duplicated.
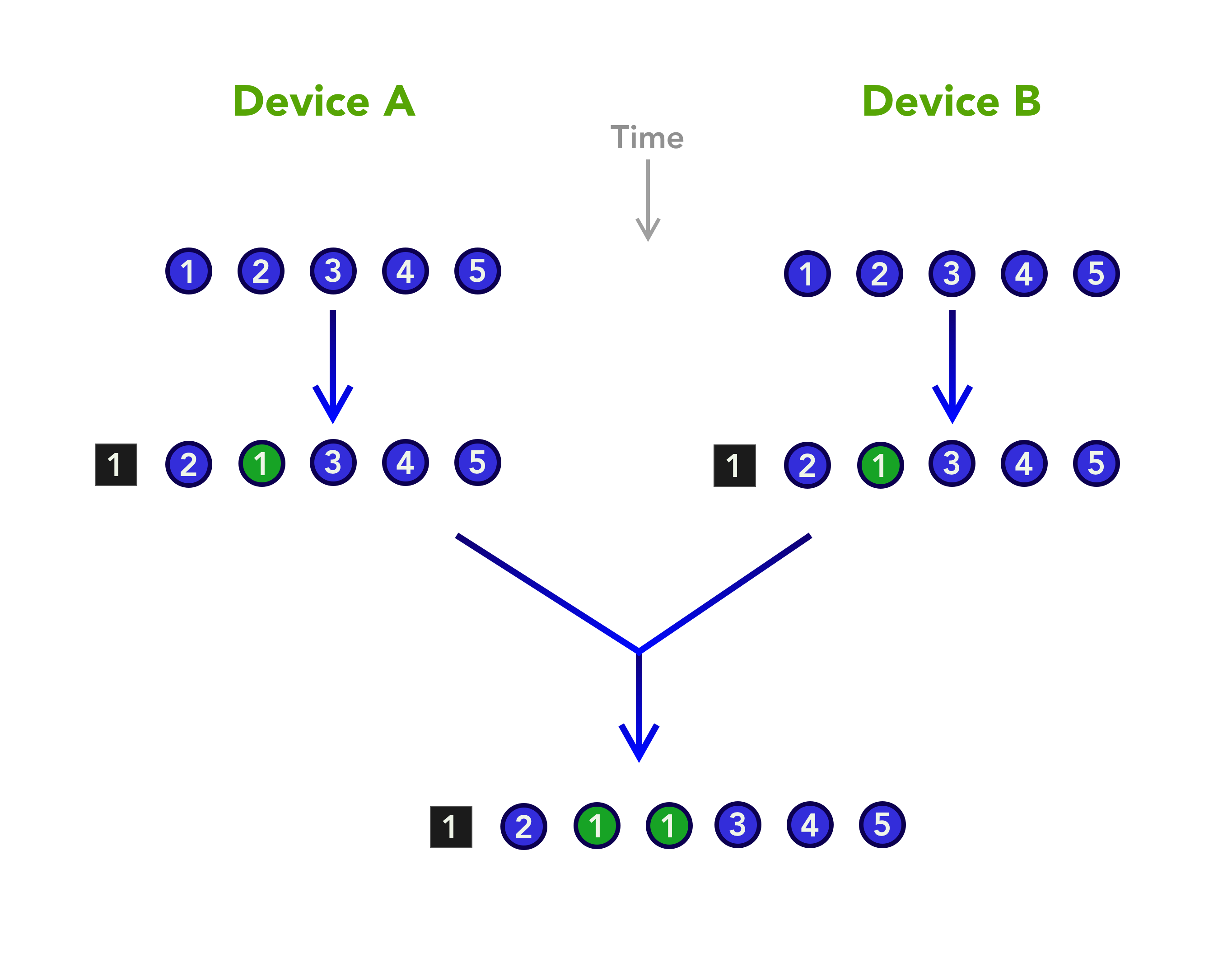
We have used the ReplicatingArray because it is the only ordered type we have in this series, but we would be much better off with a ReplicatingOrderedSet. Such a type could be developed along the lines of the ReplicatingDictionary, and would properly handle identity of entries.
Without a ReplicatingOrderedSet, I have opted instead to use the ReplicatingArray, and to explicitly check for duplicates after a merge. Most of the merge code is there to remove the duplicated entries, and checks consistency with the dictionary of notes. With the right data type at hand, this extra code would not have been needed.
That just leaves the code for merging the Note values themselves. This is trivial. It simply goes through the properties, merging each one.
func merged(with other: Note) -> Note {
assert(id == other.id)
var newNote = self
newNote.title = title.merged(with: other.title)
newNote.text = text.merged(with: other.text)
newNote.tags = tags.merged(with: other.tags)
newNote.priority = priority.merged(with: other.priority)
return newNote
}
The Decent Text Editor
I mentioned in the beginning that Decent Notes utilizes SwiftUI, and that we wouldn’t be looking into that aspect. That is mostly true. I want to detour a little to consider how we deal with edits in the text editor, to demonstrate that integrating replicating types is not always the same as when you are using standard types.
The problem is that the SwiftUI TextEditor view expects to work with a String. In particular, it uses a binding to a string to get and set its contents. Our model, on the other hand, has a ReplicatingArray<Character>, and expects to be updated with insertions and deletions of characters.
What we don’t want is to simply set the model to the new string every time it changes. This will generate a lot of data, because the ReplicatingArray stores a complete history of edits. It would also mean we will not get any meaningful merging of our replicas — they would behave atomically, like a register.
The trick is to include a bindable string for the TextEditor, but instead of just storing the new string directly in our model, we determine what changed, and apply those changes to the ReplicatingArray.
struct ReplicatingCharactersView: View {
@Binding var replicatingCharacters: ReplicatingArray<Character>
private var modelText: String { String(replicatingCharacters.values) }
@State private var displayedText: String = ""
var body: some View {
TextEditor(text: $displayedText)
.border(Color(white: 0.9))
.onAppear {
updateDisplayedTextWithModel()
}
.onChange(of: replicatingCharacters) { _ in
updateDisplayedTextWithModel()
}
.onChange(of: displayedText) { _ in
updateModelFromDisplayedText()
}
}
Note the .onAppear and .onChange modifiers; those blocks are called when the text editor first appears, and when properties change. We use these moments to see what changes we need to make in the model.
The functions that get called to establish what changed use the String.difference method to establish what is different between the new string, and the one that is already in the model. The differences are then applied to the model.
private func updateDisplayedTextWithModel() {
let modelText = self.modelText
guard displayedText != modelText else { return }
displayedText = modelText
}
private func updateModelFromDisplayedText() {
guard displayedText != modelText else { return }
let diff = displayedText.difference(from: modelText)
var newChars = replicatingCharacters
for d in diff {
switch d {
case let .insert(offset, element, _):
newChars.insert(element, at: offset)
case let .remove(offset, _, _):
newChars.remove(at: offset)
}
}
replicatingCharacters = newChars
}
Finishing Up
That’s all folks! In this series, we’ve seen how you can design and create your own replicating data types, and combine them to into full distributed data apps. These types have a data cost, but the payoff is that they make syncing more powerful and easier to implement. They also free your app from lock in — you can sync via any cloud service, and even peer-to-peer.
Where to from here? Start building apps with replicating types. Develop your own types as needed — it’s really not that difficult. In short, go forth and replicate!
Featured image from here.
